Avoid This Mistake When Caching Asynchronous Results
Implementing a robust cache is a challenging task. Some of the things you'll need to consider are — What will you cache? When will you invalidate? And, what strategy will you implement? 🤔
The primary job of a cache is to reduce load on upstream services. Therefore, last thing you want is an ineffective and useless cache. 😤
Unfortunately, this is something that happens all too often when caching asynchronous results.
Here's what you should watch out for, and how you can implement a cache that guarantees no cache misses.
Cache stampede
In the context of web applications, a cache stampede occurs when several requests are fetching the same resource in parallel. If the resource is missing from the cache, each request ends up initiating a separate database query.
To illustrate, suppose a query takes 3 seconds to complete and the incoming traffic is 10 requests per second (for the same resource). On a cache miss, we'll end up with 30 identical database queries before we start serving the resource from the cache!
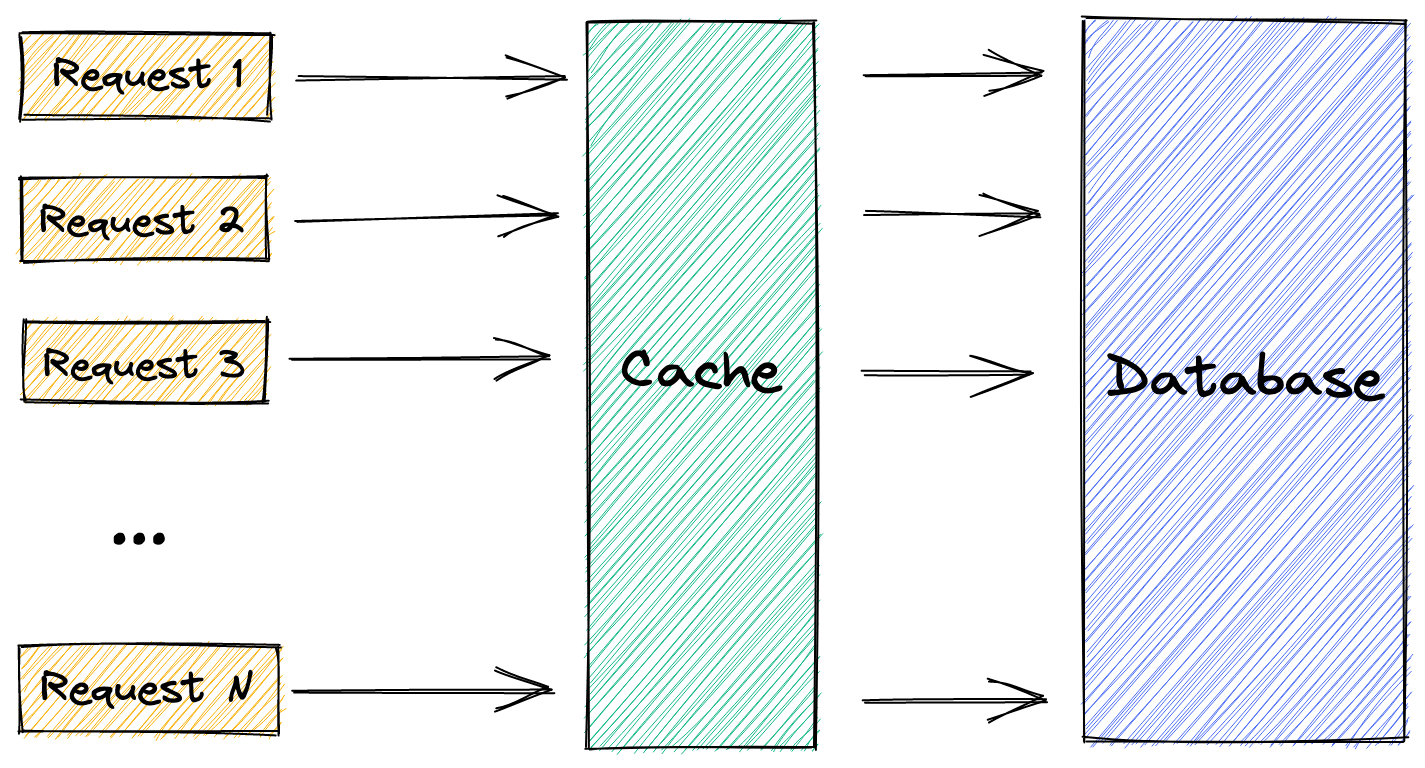
The longer it takes for a query to complete and the higher the incoming traffic, the larger the load on the database. This can result in slow response times or even a complete outage. (looking at you, Facebook)
The core of the problem is that requests aren't aware of each other. They act independently which leads to duplicate work. Ideally, requests should know about one another and reuse pending work.
One way to solve a cache stampede is to introduce a locking mechanism. On a cache miss, a request tries to acquire a lock for a particular resource and recompute it only if it has acquired a lock.
Implement locks using promises
An ingenious way of implementing a locking mechanism is to use promises. Instead of storing the value in the cache, we store the corresponding promise.
We can make use of the fact that promises are created synchronously, whereas query results are returned asynchronously. This ensures that with multiple concurrent requests, only the first request will propagate a query to the database. Subsequent requests will reuse the same promise and wait until it fulfills.
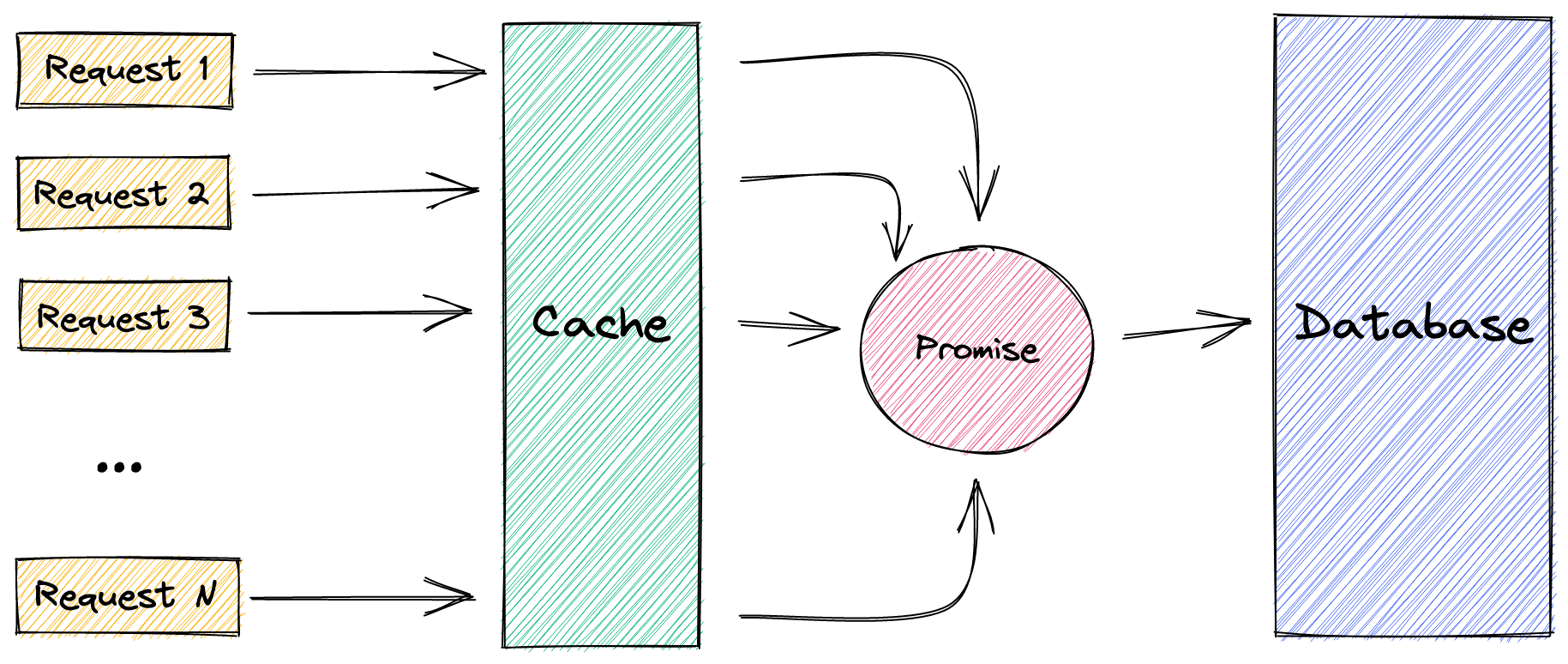
Let's look at some code.
Below, we have a getUser function that takes a user ID and returns a promise that fulfills with the user object. The function first checks if there is a promise for that particular user ID in the cache. If there is, return the promise. If there isn't, initiate a query to get the user from the database and store the resulting promise in the cache before returning it.
const userPromiseCache = new Map();
function getUser(userId) {
// If the promise is not stored in the cache, fetch the user from DB
// and store the resulting promise in the cache
if (!userPromiseCache.has(userId)) {
const userPromise = db.findUserById(userId)
.catch((error) => {
// Have the promise remove itself from the cache if it rejects
userPromiseCache.delete(userId);
return Promise.reject(error);
});
// Store promise in the cache
userPromiseCache.set(userId, userPromise);
}
// Return the promise from cache
return userPromiseCache.get(userId);
}
Notice the error handler attached to the promise. It ensures the promise will remove itself from the cache if it rejects. Otherwise, we'll end up caching the rejection and future requests will return an error. It's ok to use the .catch() method here since there's no other way. Generally though, you want to avoid mixing Promise.then() with async/await syntax.
Because the promise is created and returned synchronously, subsequent calls with the same user ID are guaranteed to reuse the same promise.
Usually, a locking mechanism involves complex logic for lock acquisition. This technique gives you simple and straightforward locks.
Memoizing promises
Seen from another angle, this cache implementation is just memoizing the getUser function. When we call the function with the same userId, we get the same cached result (a promise).
There are several libraries in the JavaScript ecosystem that help with memoization, including memoizee. We can simplify the above implementation to just:
import memoizee from "memoizee";
const getUser = memoizee(
(userId) => db.findUserById(userId),
{ promise: true }
);
With promise: true we let the library know that the function returns a promise. It will then make sure to remove promise rejections like we manually did earlier.
Looks clean, doesn't it?! ✨
You have now learned the peril of caching asynchronous values and how to avoid it. With this knowledge in hand, you're ready to implement a robust cache with more cache hits!
